Cloudflare blocks out threats and bad bots and, unfortunately for us, it also assumes all non-whitelisted bot traffic is malicious. This makes web scraping difficult since there’s a good chance our scraper will be denied access to a Cloudflare-protected web page.
One of the best ways to solve this is by using a headless browser, like Selenium, because it’s capable of imitating the activities of a real user. In this guide, we’ll discuss the most effective method to bypass Cloudflare with Selenium.
Let’s jump right in!
Selenium is a Python library used for automating web browsers and scraping web pages. Selenium extensions emulate user interaction and provide interactivity in various ways, like enabling the clicking of buttons, scrolling the page, executing custom JavaScript code, simulating user inputs and so on. It automates processes on several browsers, including Firefox and Chrome, using the Webdriver protocol.
Cloudflare is a web performance and security company that works to secure and optimize websites and applications. When it comes to security, Cloudflare offers a Web Application Firewall (WAF) that is capable of defending against web attacks, such as cross-site scripting (XSS) and DDoS attacks.
Unfortunately for us, Cloudflare Bot Management is capable of detecting Selenium. Cloudflare stops malicious HTTP traffic from moving on to the server and it performs security checks to mitigate Layer 7 (application layer) of DDoS attacks. These security checks would identify a Selenium webDriver as a bot.
On a site running with Cloudflare, an interstitial page comes up for 5 seconds. If the checks on the HTTP traffic pass as genuine, the server redirects the user to the page. If not, the page stays there and shows a CAPTCHA.
Cloudflare’s bot detection techniques can be classified into two categories: passive and active. Passive bot detection uses backend server detection techniques, like TLS fingerprinting, HTTP request headers and IP address reputation. Active bot detection happens on the client side, including CAPTCHAs, event tracking, canvas fingerprinting and others.
Yes! It’s possible to bypass Cloudflare in Selenium. While using base Selenium might not be enough, it’s possible to install extended Selenium libraries to help you avoid Cloudflare detection.
First, let’s run through a quick example to show you why base Selenium isn’t enough. We’ll be using DataCamp, a website with Cloudflare anti-bot protection.
The following tools are necessary to follow along with this tutorial.
Selenium WebDriver serves as a web automation tool, allowing you to manage web browsers. Previously, you needed to install WebDriver separately, but starting from Selenium version 4 and later, it comes bundled. If you’re using an older version, update to access the latest features and capabilities. Check your current version using pip show selenium and upgrade with pip install --upgrade selenium.
Open a terminal. In your desired directory, install Selenium.
pip install selenium
In your Python file, copy and paste the code block below.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--headless") # Headless mode
driver = webdriver.Chrome(options=options)
driver.get("https://www.datacamp.com/users/sign_in")
time.sleep(20)
driver.save_screenshot("datacamp.png")
driver.close()
Run the Python file.
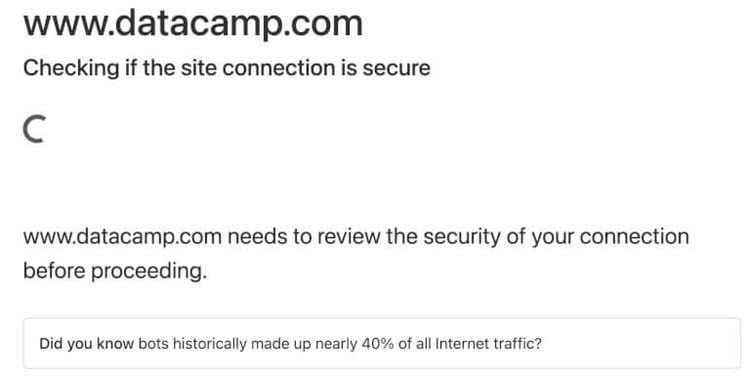
After running the script, the request came back with an error preventing access to the HTML elements, and we can’t crawl the webpage without these elements. Good one, Cloudflare, you win this one!
So how do we tweak Selenium to bypass Cloudflare? We’re getting there.
As we’ve discussed and shown, using base Selenium for Cloudflare just doesn’t work since it isn’t capable of accessing sites with complex anti-bot services. That said, let’s take a look at a few tweaks and tricks available to bypass Cloudflare Selenium.
undetected_chromedriver is a selenium.webdriver.Chrome replacement and it’s often used when there’s a need to access a site with anti-bot protection as it focuses on stealth. With undetected_chromedriver, a web-driver can be created and used to bypass bot detections, like Cloudflare.
Let’s proceed to use undetected_chromedriver to access the DataCamp sign-in page. Start by installing it.
pip install undetected-chromedriver
Create a Python file and import undetected_chromedriver.
import undetected_chromedriver as uc
Instantiate undetected_chromedriver.
driver = uc.Chrome(...)
With our instantiated driver, let’s make a successful call to DataCamp using .get() from the webdriver. time.sleep is used as an explicit wait condition to keep our window open until the process is done and the maximize_window() method is used to maximize the window if it’s not already maximized.
import undetected_chromedriver as uc
import time
options = uc.ChromeOptions()
options.headless = False # Set headless to False to run in non-headless mode
driver = uc.Chrome(use_subprocess=True, options=options)
driver.get("https://www.datacamp.com/users/sign_in")
driver.maximize_window()
time.sleep(20)
driver.save_screenshot("datacamp.png")
driver.close()
Run the created file using the Python command and the name of the file:
python scraper.py
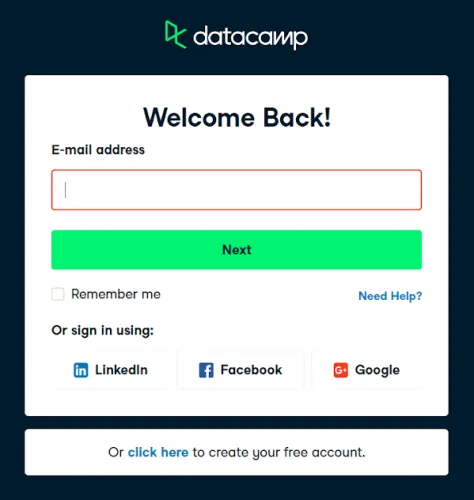
And that’s it, here’s what you’ll see:
Congratulations! You have avoided getting Selenium blocked by Cloudflare, well for now.
If you’re looking to scrape a website with basic anti-bot protection, then undetected_chromedriver might be enough for you. But when it comes to websites that use advanced Cloudflare protection and other DDoS mitigation services, undetected_chromedriver can be unreliable.
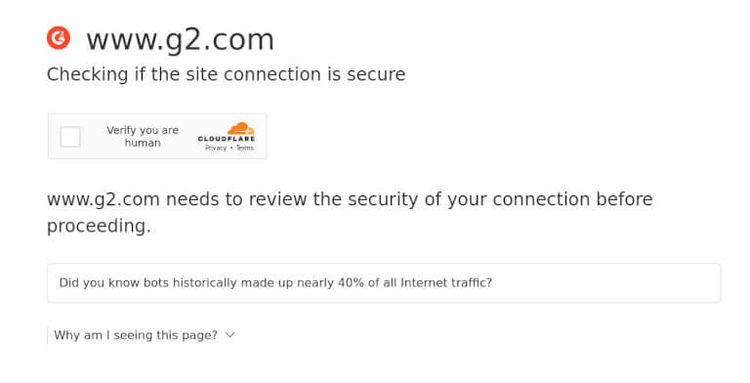
For example, we tried to access the Asana page on g2.com using undetected_chromedriver and the steps shared above. Do you want to know what happened? We got blocked.
As you can see, undetected_chromedriver failed because the G2 anti-bot service detected that our browser session was automated. So how do we solve this problem? Easy: using ZenRows.
ZenRows is a web scraping tool capable of bypassing different types of antibots, even complex ones, with a simple API call. And yes, it can bypass Cloudflare without stress. Let’s see how.
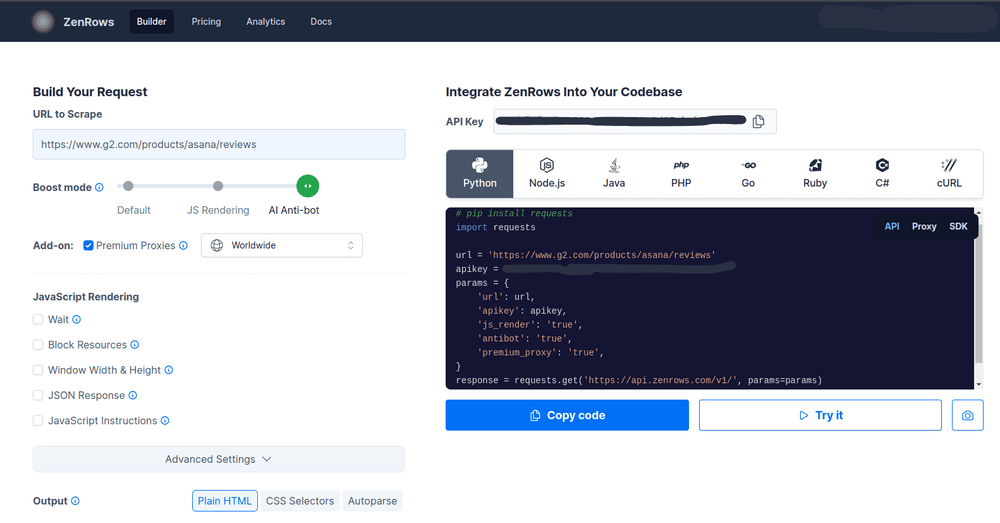
To get started, create a free ZenRows account and navigate to the Request Builder. We’ll be using Zenrows API, so click on Python and select API from the options on the screen. Paste the URL to scrape, enable Javascript rendering, and Antibot. ZenRows will automatically generate a Python web scraping script for you.
Copy the code generated and paste it into your Python file.
# pip install requests
import requests
url = 'https://www.g2.com/products/asana/reviews'
apikey = '<YOUR_ZENROWS_API_KEY>'
params = {
'url': url,
'apikey': apikey,
'js_render': 'true',
'antibot': 'true',
'premium_proxy': 'true',
}
response = requests.get('https://api.zenrows.com/v1/', params=params)
print(response.text)
The final step is to run the script in the terminal.
python scraper.py
Boom! Just like that, we have our output:
C’est fini, you’ve successfully bypassed Cloudflare with ZenRows!
OpenAi 官方的Strea...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}